
Um auf das Wesentliche zurückzukommen: Der Durchbruch von AIGC in Sachen Singularität ist eine Kombination aus drei Faktoren:
1. GPT ist eine Nachbildung menschlicher Neuronen
Die durch NLP repräsentierte GPT-KI ist ein Computeralgorithmus für neuronale Netzwerke, dessen Kern darin besteht, neuronale Netzwerke in der menschlichen Großhirnrinde zu simulieren.
Die Verarbeitung und intelligente Vorstellung von Sprache, Musik, Bildern und sogar Geschmacksinformationen sind alles Funktionen, die der Mensch ansammelt
Gehirn als „Proteincomputer“ während der langfristigen Evolution.
Daher ist GPT natürlich die am besten geeignete Nachahmung für die Verarbeitung ähnlicher Informationen, also unstrukturierter Sprache, Musik und Bilder.
Der Mechanismus seiner Verarbeitung ist nicht das Verstehen von Bedeutung, sondern ein Prozess der Verfeinerung, Identifizierung und Assoziation.Das ist ein sehr
paradoxe Sache.
Frühe semantische Spracherkennungsalgorithmen erstellten im Wesentlichen ein Grammatikmodell und eine Sprachdatenbank und ordneten dann die Sprache dem Vokabular zu.
Anschließend wurde das Vokabular in die Grammatikdatenbank eingefügt, um die Bedeutung des Vokabulars zu verstehen, und schließlich wurden Erkennungsergebnisse erzielt.
Die Erkennungseffizienz dieser auf „logischen Mechanismen“ basierenden Syntaxerkennung liegt bei rund 70 %, wie beispielsweise bei der ViaVoice-Erkennung
Algorithmus, der in den 1990er Jahren von IBM eingeführt wurde.
Bei AIGC geht es nicht darum, so zu spielen.Sein Wesen besteht nicht darin, sich um die Grammatik zu kümmern, sondern vielmehr darum, einen neuronalen Netzwerkalgorithmus zu etablieren, der dies ermöglicht
Computer, um die probabilistischen Verbindungen zwischen verschiedenen Wörtern zu zählen, bei denen es sich um neuronale Verbindungen und nicht um semantische Verbindungen handelt.
Ähnlich wie wir in jungen Jahren unsere Muttersprache gelernt haben, haben wir sie auf natürliche Weise gelernt, anstatt „Subjekt, Prädikat, Objekt, Verb, Komplement“ zu lernen.
und dann einen Absatz verstehen.
Dies ist das Denkmodell der KI, das auf Erkennen und nicht auf Verstehen basiert.
Darin liegt auch die subversive Bedeutung der KI für alle klassischen Mechanismusmodelle – Computer müssen diese Materie nicht auf der logischen Ebene verstehen,
sondern vielmehr die Korrelation zwischen internen Informationen identifizieren und erkennen und sie dann kennen.
Der Leistungsflusszustand und die Vorhersage von Stromnetzen basieren beispielsweise auf der klassischen Stromnetzsimulation, bei der ein mathematisches Modell der
Der Mechanismus wird etabliert und dann mithilfe eines Matrixalgorithmus konvergiert.In Zukunft ist dies möglicherweise nicht mehr erforderlich.KI wird a direkt identifizieren und vorhersagen
bestimmtes modales Muster basierend auf dem Status jedes Knotens.
Je mehr Knoten vorhanden sind, desto weniger beliebt ist der klassische Matrixalgorithmus, da die Komplexität des Algorithmus mit der Anzahl der Knoten zunimmt
Knoten und der geometrische Verlauf nimmt zu.KI bevorzugt jedoch eine sehr große Knotenparallelität, da KI gut darin ist, zu identifizieren und
Vorhersage der wahrscheinlichsten Netzwerkmodi.
Sei es die nächste Vorhersage von Go (AlphaGO kann die nächsten Dutzende Schritte vorhersagen, mit unzähligen Möglichkeiten für jeden Schritt) oder die modale Vorhersage
Bei komplexen Wettersystemen ist die Genauigkeit von KI viel höher als bei mechanischen Modellen.
Der Grund, warum das Stromnetz derzeit keine KI erfordert, liegt darin, dass die Anzahl der Knoten in Stromnetzen mit 220 kV und höher von der Provinz verwaltet wird
Der Versand ist nicht groß, und es werden viele Bedingungen festgelegt, um die Matrix zu linearisieren und zu spärlich zu machen, wodurch die Rechenkomplexität der Matrix erheblich reduziert wird
Mechanismusmodell.
Auf der Ebene des Stromflusses im Verteilungsnetz stehen jedoch Zehntausende oder Hunderttausende von Stromknoten, Lastknoten und herkömmlichen Knoten zur Verfügung
Matrixalgorithmen sind in einem großen Vertriebsnetz machtlos.
Ich glaube, dass die Mustererkennung von KI auf der Ebene des Vertriebsnetzes in Zukunft möglich sein wird.
2. Die Ansammlung, Schulung und Generierung unstrukturierter Informationen
Der zweite Grund für den Durchbruch von AIGC ist die Anhäufung von Informationen.Aus der A/D-Wandlung von Sprache (Mikrofon+PCM
Vom Abtasten bis hin zur A/D-Umwandlung von Bildern (CMOS + Farbraumkartierung) haben Menschen holografische Daten im visuellen und akustischen Bereich angesammelt
Felder in den letzten Jahrzehnten auf äußerst kostengünstige Weise erschlossen haben.
Insbesondere die großflächige Popularisierung von Kameras und Smartphones, die Anhäufung unstrukturierter Daten im audiovisuellen Bereich für den Menschen
nahezu zum Nulltarif und die explosionsartige Anhäufung von Textinformationen im Internet sind der Schlüssel zum AIGC-Training – Trainingsdatensätze sind kostengünstig.
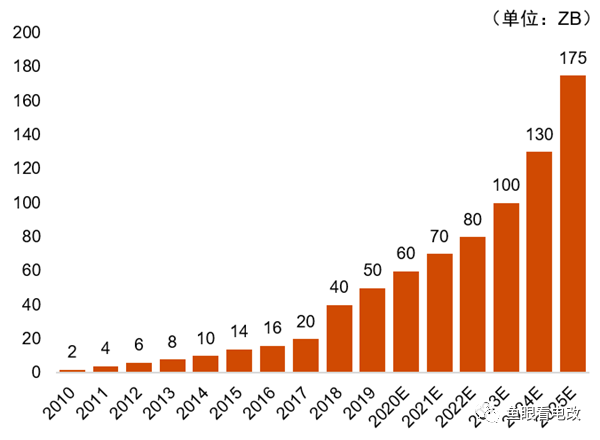
Die obige Abbildung zeigt den Wachstumstrend der globalen Daten, der eindeutig einen exponentiellen Trend darstellt.
Dieses nichtlineare Wachstum der Datenakkumulation ist die Grundlage für das nichtlineare Wachstum der Fähigkeiten von AIGC.
ABER die meisten dieser Daten sind unstrukturierte audiovisuelle Daten, die kostenlos gesammelt werden.
Im Bereich der elektrischen Energie ist dies nicht zu erreichen.Erstens besteht der Großteil der Elektrizitätswirtschaft aus strukturierten und halbstrukturierten Daten, wie z
Spannung und Strom, bei denen es sich um Punktdatensätze aus Zeitreihen und halbstrukturierter Form handelt.
Strukturelle Datensätze müssen von Computern verstanden werden und erfordern eine „Ausrichtung“, beispielsweise die Geräteausrichtung – die Spannungs-, Strom- und Leistungsdaten
eines Switches müssen auf diesen Knoten ausgerichtet werden.
Noch problematischer ist die zeitliche Ausrichtung, bei der Spannung, Strom sowie Wirk- und Blindleistung auf der Zeitskala abgeglichen werden müssen
Eine anschließende Identifizierung kann durchgeführt werden.Es gibt auch Vorwärts- und Rückwärtsrichtungen, die in vier Quadranten räumlich ausgerichtet sind.
Im Gegensatz zu Textdaten, die keiner Ausrichtung bedürfen, wird ein Absatz einfach an den Computer übergeben, der mögliche Informationszusammenhänge identifiziert
von allein.
Um dieses Problem auszurichten, z. B. die Geräteausrichtung von Geschäftsverteilungsdaten, ist eine ständige Ausrichtung erforderlich, da das Medium und
Im Niederspannungsverteilungsnetz werden täglich Geräte und Leitungen hinzugefügt, gelöscht und geändert, und die Netzbetreiber investieren enorme Arbeitskosten.
Wie bei der „Datenanmerkung“ können Computer dies nicht tun.
Zweitens sind die Kosten für die Datenerfassung im Energiesektor hoch und es werden Sensoren anstelle eines Mobiltelefons zum Sprechen und Fotografieren benötigt.”
Jedes Mal, wenn die Spannung um eine Stufe abnimmt (oder das Verhältnis der Stromverteilung um eine Stufe abnimmt), erhöht sich die erforderliche Sensorinvestition
um mindestens eine Größenordnung.Um eine lastseitige (Kapillarende-)Abtastung zu erreichen, ist es sogar noch eine gewaltige digitale Investition.“
Wenn es notwendig ist, den Übergangsmodus des Stromnetzes zu identifizieren, ist eine hochpräzise Hochfrequenzabtastung erforderlich, und die Kosten sind noch höher.
Aufgrund der extrem hohen Grenzkosten der Datenerfassung und des Datenabgleichs ist das Stromnetz derzeit nicht in der Lage, ausreichend nichtlineare Daten zu akkumulieren
Wachstum von Dateninformationen, um einen Algorithmus zu trainieren, um die KI-Singularität zu erreichen.
Ganz zu schweigen von der Offenheit der Daten: Es ist für ein Power-KI-Startup unmöglich, an diese Daten zu gelangen.
Daher ist es vor der KI notwendig, das Problem der Datensätze zu lösen, da sonst der allgemeine KI-Code nicht trainiert werden kann, um eine gute KI zu erzeugen.
3. Durchbruch in der Rechenleistung
Neben Algorithmen und Daten ist der Singularitätsdurchbruch von AIGC auch ein Durchbruch bei der Rechenleistung.Herkömmliche CPUs sind das nicht
Geeignet für groß angelegtes gleichzeitiges neuronales Rechnen.Gerade der Einsatz von GPUs in 3D-Spielen und -Filmen macht groß angelegte Parallelen möglich
Fließkomma- und Streaming-Computing möglich.Das Mooresche Gesetz reduziert die Rechenkosten pro Rechenleistungseinheit weiter.
Stromnetz-KI, ein unvermeidlicher Trend in der Zukunft
Mit der Integration einer großen Anzahl verteilter Photovoltaik- und dezentraler Energiespeichersysteme sowie den Anwendungsanforderungen von
Bei lastseitigen virtuellen Kraftwerken ist es objektiv notwendig, Quellen- und Lastprognosen für öffentliche Verteilnetze und Nutzer durchzuführen
Verteilungs-(Mikro-)Netzsysteme sowie Echtzeit-Leistungsflussoptimierung für Verteilungs-(Mikro-)Netzsysteme.
Der Rechenaufwand auf der Seite des Verteilungsnetzes ist tatsächlich höher als der der Übertragungsnetzplanung.Sogar für einen Werbespot
komplex, es kann Zehntausende von Lastgeräten und Hunderte von Schaltern geben und die Nachfrage nach einem KI-basierten Betrieb von Mikronetzen/Verteilungsnetzen besteht
Kontrolle entsteht.
Angesichts der geringen Kosten von Sensoren und der weit verbreiteten Verwendung leistungselektronischer Geräte wie Halbleitertransformatoren, Halbleiterschalter und Wechselrichter (Wandler)
Auch die Integration von Sensorik, Berechnung und Steuerung am Rande des Stromnetzes ist zu einem innovativen Trend geworden.
Daher ist die AIGC des Stromnetzes die Zukunft.Was heute jedoch benötigt wird, ist nicht, sofort einen KI-Algorithmus auszuschalten, um Geld zu verdienen, sondern
Behandeln Sie stattdessen zunächst die für die KI erforderlichen Probleme beim Aufbau der Dateninfrastruktur
Angesichts des Aufschwungs von AIGC muss ausreichend Ruhe über die Anwendungsebene und die Zukunft der Power-KI nachgedacht werden.
Derzeit ist die Bedeutung von Power AI nicht von Bedeutung: Beispielsweise wird ein Photovoltaik-Algorithmus mit einer Vorhersagegenauigkeit von 90 % auf dem Spotmarkt platziert
mit einem Handelsabweichungsschwellenwert von 5 %, und die Algorithmusabweichung wird alle Handelsgewinne zunichte machen.
Die Daten sind Wasser und die Rechenleistung des Algorithmus ist ein Kanal.So wie es kommt, wird es so sein.
Zeitpunkt der Veröffentlichung: 27. März 2023